机器学习模型互相教导识别分子特性
发布时间:2024-01-22 10:42:36来源:
杜克大学的生物医学工程师开发了一种新方法来提高机器学习模型的有效性。通过将两种机器学习模型配对,一种用于收集数据,另一种用于分析数据,研究人员可以在不牺牲准确性的情况下规避技术的局限性。
这项新技术可以使研究人员更轻松地使用机器学习算法来识别和表征分子,以用于潜在的新疗法或其他材料。
该研究发表在《生命科学人工智能》杂志上。
在传统的机器学习模型中,研究人员将输入数据集,模型将使用该信息进行预测。虽然这通常是有效的,但这些工具的能力受到用于训练它们的数据集的限制,这些数据集通常可能缺乏关键信息或包含过多的一种数据类型,从而在模型中引入偏差。
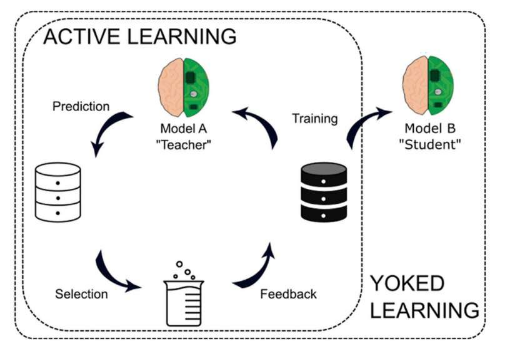
相反,研究人员开发了一种称为主动机器学习的技术,如果模型感知到数据中存在差距,它就能够提出问题或请求更多信息。这种提问能力使模型比被动模型更加准确和高效。
尽管主动学习对于机器学习模型非常有效,但该技术在应用于更复杂的深度神经网络时遇到了严重的局限性。这些深度学习模型旨在模仿人脑,需要比通常可用的更多的数据和计算能力,从而限制了它们的准确性和有效性。
Reker 和他的团队想要确定一种称为“轭学习”的教育概念是否可以应用于机器学习领域以改进这些系统。
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。