人工智能系统可以使用静态图像将语音轨道转换为人说话的视频
发布时间:2024-03-04 10:53:55来源:
阿里巴巴集团智能计算研究院的一个人工智能研究人员小组通过他们创建的视频演示了一款新的人工智能应用程序,该应用程序可以接受一张人脸照片以及某人说话或唱歌的配乐,并使用它们来创建说话或演唱音轨的人的动画版本。该小组发表了一篇论文,描述了他们在arXiv预印本服务器上的工作。
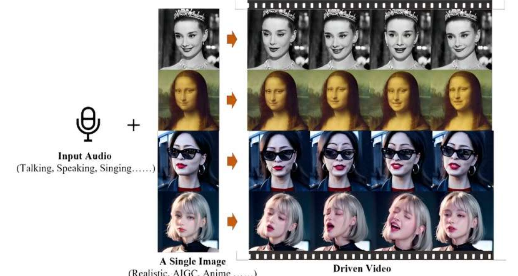
先前的研究人员已经演示了人工智能应用程序,可以处理脸部照片并用它来创建半动画版本。在这项新的努力中,阿里巴巴团队通过添加声音更进一步。也许,同样重要的是,他们在没有使用 3D 模型甚至面部标志的情况下就做到了这一点。相反,该团队使用了基于在大型音频或视频文件数据集上训练人工智能的扩散建模。在本例中,该团队使用了大约 250 小时的此类数据来创建他们的应用程序,他们将其称为 Emote Portrait Alive ( EMO )。
通过直接将音频波形转换为视频帧,研究人员创建了一个应用程序,可以捕获微妙的人类面部姿势、言语怪癖以及其他特征,从而将动画图像识别为人类面部。这些视频忠实地再现了用于形成单词和句子的可能的嘴形,以及通常与之相关的表情。
该团队发布了多个视频,展示了他们生成的惊人准确的性能,并声称它们在真实性和表现力方面优于其他应用程序。他们还指出,完成的视频长度是由原始音轨的长度决定的。在视频中,原始图片与该人一起显示,该人以原始音轨上录制的声音说话或唱歌。
(责编: BAZHONG)
版权声明:网站作为信息内容发布平台,为非经营性网站,内容为用户上传,不代表本网站立场,不承担任何经济和法律责任。文章内容如涉及侵权请联系及时删除。




